Contents
Introduction
Viola and Jones in their great paper 'Robust Real-Time Face Detection' introduced fast object detection using Haar-like features and a cascade of classifiers. That approach is freely available in the public OpenCV library. After I wrote the PCA based Face Detection library, I wanted to develop something similar to the Haar based object detection for a faster image processing than the baseline PCA detector could allow. In this article, I present my own version of theHaar based object detector. I used my already developed helper classes from my previous articles you may find at the links below. Viola and Jones used 160000 rectangular features, so the cascade of classifiers is large. In my version, I manually devised only 115 rectangular features that closely mimics Eigenfaces PCA basis. Also, I used artificial neural networks (ANNs) as classifiers in a cascade. So my tasks were to develop the code library and investigate if the very small subset of features will result in robust object detection with non-linear classifiers. For the object, I used the face detection problem, thanks to the great face databases as CBCL or CMU thatv are available to solve the problem.
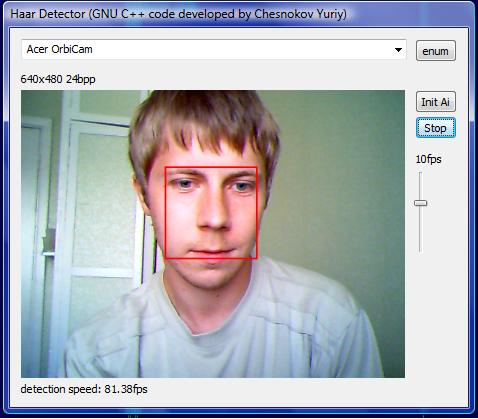
To start with the executable, just click the enum button and select the capture device, then click Init AI to load the cascade of ANN classifiers and push the Start button to initiate the capture and face detection. You can alter the capture rate with the slider control. At the bottom status static, the detection fps will be shown.
One precaution, compared to my Eigenfaces face detection lib, there you can get every individual rectangle and histogram equalized before further processing; you can not do the same trick with an integral image. Only adaptive histogram equalization will work for the entire image before computing the integral version of it. So the presented classifiers might not be as good to bad lighting conditions as the Eigenfaces code. So make sure you've got your face lit enough from the front.
Background
Some computer vision and AI basics are desired. If you completely understand my previous Face Detection article, you will have no hurdles in comprehending this code. You may also read Viola and Jones' paper about Haar-likefeatures and its extraction from an integral image. Otherwise this article should be sufficient to understand the method.
The Algorithm
Integral Image
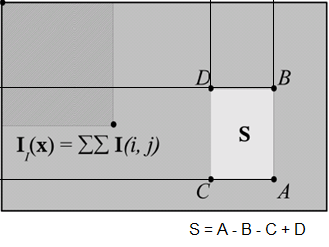
The concept of integral image is very simple. You preprocess the image to significantly increase the extraction ofHaar-like features for analysis and object detection. At any point (i, j) in the original image, you sum up all the pixels to the left and up from that point (i, j): I(x) = sum sum I(i, j).
So the code could look like this snippet:
 Collapse
Collapse |
Copy Codeunsigned char** pimage;
unsigned int** pintegral_image;
for (unsigned int i = 0; i < height; i++) {
for (unsigned int j = 0; j < width; j++) {
pintegral_image[i][j] = 0;
for (unsigned int y = 0; y <= i; y++)
for (unsigned int x = 0; x <= j; x++)
pintegral_image[i][j] += pimage[y][x];
}
}However, you may speed up the process by adding the sums from the previous step:
Collapse |
Copy Code
unsigned char** pimage;
unsigned int** pintegral_image;
unsigned int** v = pintegral_image;
for (unsigned int i = 1; i < height; i++)
v[i][0] += v[i - 1][0];
for (unsigned int j = 1; j < width; j++)
v[0][j] += v[0][j - 1];
for (unsigned int i = 1; i < height; i++)
for (unsigned int j = 1; j < width; j++)
v[i][j] += (v[i][j - 1] + v[i - 1][j]) - v[i - 1][j - 1];After that point, to get the sum of all pixel values inside the S rectangle, we need only four array references: S = A - B - C + D, where A, B, C, D are the points in the integral image.
Haar-like Features
The features consist of boxes of different sizes and locations. Consider some 20x20 rectangle; you may place, for example, inside it two rectangles of size 10x20 or four rectangles with size 10x10 etc... Devising such an over complete feature set is quite a task, configuring every possible combination in turn. Having such a feature basis of 20x20 rectangular features, you project the image to that set. Keeping in mind that you have the integral image, such a projection step takes an infinitesimally small amount of time. For a feature consisting of two rectangles of 10x20 size, you compute the sum of all the pixels in that 10x20 rectangles as was pointed in the previous section, so 4*2 = 8 array references, instead of an ordinary floating point matrix multiplication taking 2*20*20 = 800 operations.
I managed to implement 115 Haar features of different number of boxes. All you have to do is use consecutive grid divisions of the rectangle to 1x2, 2x1, 2x2, 3x1, 1x3, 3x2, 2x3 boxes etc... With that method, I approached features consisting of 5x4 and 4x5 boxes. They are encoded in text files as left, top and right, bottom coordinates in unit length vectors. So the above mentioned 20x20 rectangle consists of two 10x20 boxes represented as:
Collapse |
Copy Code
feature2x1_1 2
0.00 0.00 0.50 1.00 1
0.50 0.00 1.00 1.00 -1
The Haar feature consisting of four 10x10 rectangles would then be written as:
Collapse |
Copy Code
feature2x2_1 4
0.00 0.00 0.50 0.50 1
0.50 0.00 1.00 0.50 -1
0.00 0.50 0.50 1.00 -1
0.50 0.50 1.00 1.00 1
Pluses and minuses 1 are the signs of the rectangular boxes. So having the sums from the integral image of each box, you add them up considering the minus sign, which results in additions and subtractions.
Bellow are presented the 115 Haar features encoded in my application:
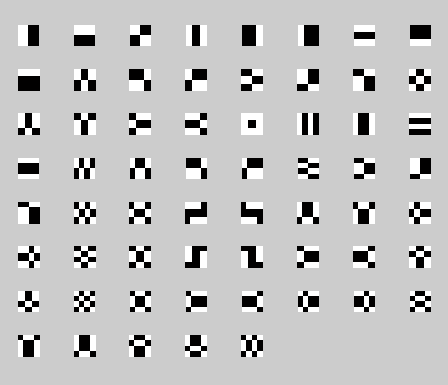
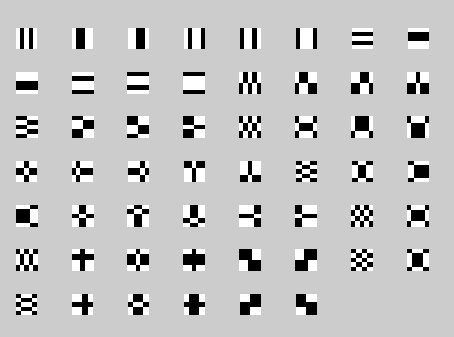
If you compare the PCA projection basis from my Face Detection article, you will notice some similarities betweenHaar features and PCA basis found from solving the Eigenvalue problem. Especially for the first two vectors.

In fact, Haar features look like quantized PCA basis, so the good accuracy of detection is expected with Haar basis also.
For the training, I used 19x19 face sets from the CBCL and CMU databases. Also, my own 19x19 face/non-face sets from the previous face detection article. In total, there were 3783 faces and 41596 non-faces.
The error bar plot of the projected face/non-face data is presented below:
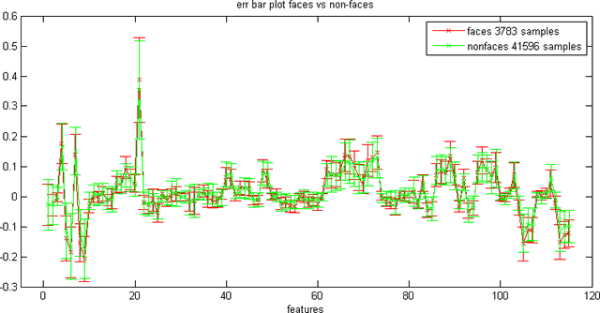
The faces are actually embedded in the non-faces as we can see from some scatter plots:
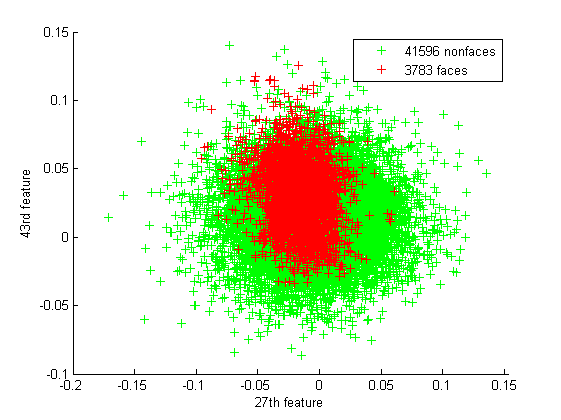
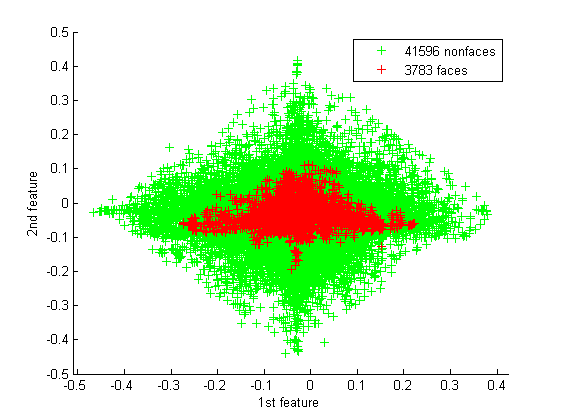
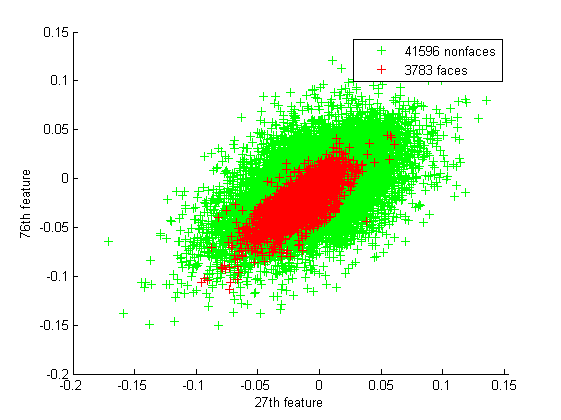
So it looks like 115D sphere of face samples inside another 115D representing all the other non-faces.
Cascade of Classifiers
To speed up the detection of the object, the cascade of neural networks classifiers is used. But you may train and add your own, e.g., SVM, kNN, etc... But I consider neural networks better suited for that purpose; besides that, it produces a non-linear separation boundary, and you may control the size of the network, the number of hidden neurons, and the classification performance during the cross-validation process. Also, I have developed the SSE optimized code for ANN classification. But if you have in mind the code for a better classifier producing better classification precision at a smaller size of the classifier (in terms of support vectors, nearest neighbours, decision rules, etc...), let me know and I will add it here by all means.
For the first stages of cascade, we are interested in rejecting the vast majority of non-objects, but we must also not miss the true objects. So the geometric mean of sensitivity and positive predictivity will suite as a validation metric. For the last stages, I change the validation metric to the geometric mean of specificity and positive predictivity so if the object is detected, it is the object indeed with high positive predictivity.
I used nine classifiers in all. The last one computes all 115 features and gives the best classification rate. The previous stages use 3, 9, 15, 21, 33, 49, 61, and 81 features. Adding more features to the classifier increases the classification accuracy. The first classifier computes three Haar features and classifies the rectangle. If it produces a negative classification result, the rectangle is considered as non-object, otherwise the next classifier is used. If the next classifier provides a negative decision, the rectangle is classified as a non-object, and again, in case of a positive decision, the rectangle is passed to the next stage. So in order for the object to be recognized, all nine classifiers should produce positive decision.
To reuse the already computed features for the later stage classifiers, they employ the features from the previous stage. So for the second stage classifier that consists of nine features, three features are already computed, so it uses them and computes only 9 - 3 = 6 features.
The corresponding network topologies are presented below:
Collapse |
Copy Code
3-20-1
9-20-1
15-10-1
21-10-1
33-15-1
49-20-1
61-20-1
81-30-1
115-20-10-5-1
The classifiers' accuracies in terms of sensitivity (Se), specificity (Sp), positive predictivity (Pp), and negative predictivity (Np) are presented below:

As you can see, the first classifier 3-20-1 ANN has a high Se at low Pp and low Sp, so the possible face will not be missed. As for the next stages, the Pp rate increases so we may trust each next classifier with more confidence.
Training times with 50% for validation and test running at low power consumption processor mode are shown below:
Collapse |
Copy Code
3-20-1 3 minutes (not converged to desired targets within 0.25 error after 100 epochs)
9-20-1 5 minutes (not converged to desired targets within 0.10 error after 100 epochs)
15-10-1 3 minutes (not converged to desired targets within 0.10 error after 100 epochs)
21-10-1 4 minutes (nearly converged to desired targets after 100 epochs)
33-15-1 7 minutes (converged after 79 epochs)
49-20-1 2.5 minutes (converged after 40 epochs)
61-20-1 2.5 minutes (converged after 36 epochs)
81-30-1 3.5 minutes (converged after 22 epochs)
115-20-10-5-1 10.5 minutes (nearly converged to desired targets after 100 epochs)
One of the training sessions for the 81-30-1 network is presented below, but you may inspect all the .nn files manually.
Collapse |
Copy Code
loading data...
cls1: 3783 cls2: 41596 files loaded. size: 81 samples
validaton size: 945 10399
test size: 993 10918
training...
epoch: 1 out: 0.686958 0.323600 max acur: 0.74 (epoch 1) se:77.35 sp:91.10 ac:89.96
epoch: 2 out: 0.742480 0.262691 max acur: 0.76 (epoch 2) se:79.37 sp:92.10 ac:91.03
epoch: 3 out: 0.768989 0.233445 max acur: 0.76 (epoch 2) se:79.37 sp:92.10 ac:91.03
epoch: 4 out: 0.788141 0.213834 max acur: 0.80 (epoch 4) se:84.66 sp:93.66 ac:92.91
epoch: 5 out: 0.803318 0.196517 max acur: 0.80 (epoch 4) se:84.66 sp:93.66 ac:92.91
epoch: 6 out: 0.814795 0.184207 max acur: 0.80 (epoch 4) se:84.66 sp:93.66 ac:92.91
epoch: 7 out: 0.822719 0.175824 max acur: 0.80 (epoch 4) se:84.66 sp:93.66 ac:92.91
epoch: 8 out: 0.827874 0.169679 max acur: 0.89 (epoch 8) se:81.38 sp:97.17 ac:95.86
epoch: 9 out: 0.835296 0.162932 max acur: 0.89 (epoch 8) se:81.38 sp:97.17 ac:95.86
epoch: 10 out: 0.842036 0.155374 max acur: 0.89 (epoch 8) se:81.38 sp:97.17 ac:95.86
epoch: 11 out: 0.845221 0.149695 max acur: 0.89 (epoch 8) se:81.38 sp:97.17 ac:95.86
epoch: 12 out: 0.848947 0.147794 max acur: 0.90 (epoch 12) se:86.03 sp:97.23 ac:96.30
epoch: 13 out: 0.850813 0.144661 max acur: 0.95 (epoch 13) se:71.01 sp:98.98 ac:96.65
epoch: 14 out: 0.853118 0.142426 max acur: 0.95 (epoch 13) se:71.01 sp:98.98 ac:96.65
epoch: 15 out: 0.854854 0.140098 max acur: 0.95 (epoch 13) se:71.01 sp:98.98 ac:96.65
epoch: 16 out: 0.858112 0.136357 max acur: 0.95 (epoch 13) se:71.01 sp:98.98 ac:96.65
epoch: 17 out: 0.859430 0.134484 max acur: 0.95 (epoch 13) se:71.01 sp:98.98 ac:96.65
epoch: 18 out: 0.861730 0.132920 max acur: 0.95 (epoch 13) se:71.01 sp:98.98 ac:96.65
epoch: 19 out: 0.862495 0.131201 max acur: 0.95 (epoch 13) se:71.01 sp:98.98 ac:96.65
epoch: 20 out: 0.864796 0.128517 max acur: 0.95 (epoch 13) se:71.01 sp:98.98 ac:96.65
epoch: 21 out: 0.866978 0.125772 max acur: 0.95 (epoch 13) se:71.01 sp:98.98 ac:96.65
epoch: 22 out: 0.868416 0.125138 max acur: 0.95 (epoch 13) se:71.01 sp:98.98 ac:96.65
training done.
training time: 00:03:31:938
The computation speed of the classification cascade consisted of 0 to 8 stages before the last 115-20-10-15-1 ANN classifier estimated on a 2.2Ghz 64Turion single core processor using the entire 80x60 image and searching for a 19x19 face (which is equivalent of looking at a 152x152 face object at a 640x480 image) is presented below:
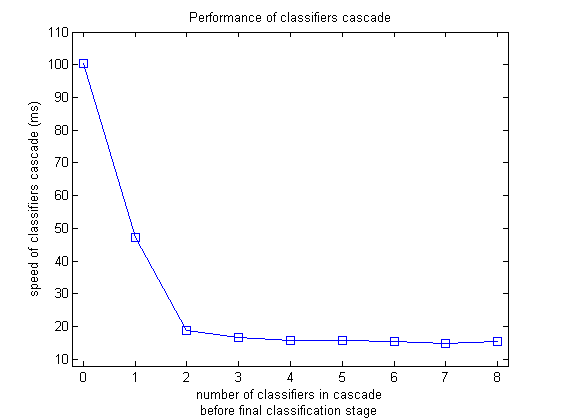
Introducing the 1 and 2 classifiers before the final one significantly reduces the computation speed. However, later stages do not provide such a decrease, but there is no significant increase either.
The Code
The lib resides under the \ai and \dshow folders. The first is the object detection implementation and the second is the video capture logic.
You may use these two classes to enumerate the available video devices and for grabbing raw bitmap data:
VideoDevicesVideoCapture
VideoDevices provides a single static function:
static HRESULT VideoDevices::Enumerate(std::vector<std::wstring>& names);
It will put the found video capture devices to the names std::vector array.
Using the found device name, you may connect to the device, start it, and grab image data at any desired fps with:
int VideoCapture::Connect(const wchar_t* deviceName);int VideoCapture::Start();int VideoCapture::Stop();const BYTE* VideoCapture::GrabFrame();
The int functions return zero upon success; GrabFrame() returns zero in case the ISampleGrabber is not ready, or a pointer to the captured frame in case of success.
You may query the video stream parameters with:
const BITMAPINFOHEADER& VideoCapture::GetBitmapInfoHeader();
The Graph is arranged as WebCam -> Sample Grabber -> Null Renderer so you have to plot the bitmap data with your own efforts, no video window is implemented.
There are some helper classes available, you may consider reading my following articles:
vec2Di is added as a wrapper for int 2D array to hold the integral image.
AiClassifier is augmented with the constructor which loads a features text file with the corresponding AI classifier ANN or SVM:
AiClassifier(const wchar_t* classifier_file, const wchar_t* features_file, const std::vector<ObjectSize>& objsizes);
objsizes holds an array of the object size structures you want to detect (e.g., 19x19, 20x10 or 50x35 etc...)
So now, you may use AiClassifier as an ordinary classifier, e.g., for skin detection, but also as a Haar featureextractor and classifier in a class:
inline int AiClassifier::classify(const float* x, float* y);inline int AiClassifier::classify(const vec2Di& integral_image, unsigned int obj_index, unsigned int dx, unsigned int dy, float* out, const AiClassifier* pprev = 0);
Collapse |
Copy Code
inline int AiClassifier::classify(const float* x, float* y)
{
if (m_status == ERR)
return 0;
double dy;
int s = 0;
switch (m_ai_type) {
case SVM:
s = m_svm->classify(x, dy);
y[0] = float(dy);
return s;
case ANN:
case TANH_ANN:
m_ann->classify(x, y);
s = sign(y[0]);
return s;
case SIGMOID_ANN:
m_ann->classify(x, y);
s = sign(y[0] - 0.5f);
return s;
default:
*y = 0.0f;
return 0;
}
}or:
Collapse |
Copy Code
inline int AiClassifier::classify(const vec2Di& integral_image, unsigned int obj_index,
unsigned int dx, unsigned int dy,
float* out,
const AiClassifier* pprev)
{
if (m_status != (CLASSIFIER | FEATURE_EXTRACTOR))
return 0;
const HaarFeatures* pprev_features = 0;
if (pprev != 0)
pprev_features = pprev->get_features(obj_index);
HaarFeatures* phf = m_features[obj_index];
if (phf->estimate(integral_image, dx, dy, pprev_features) <= 0)
return 0;
const float* x = phf->get_feature_vector().data(0, 0);
return classify(x, out);
}The HaarFeatures class is used to load features from a text file in the AiClassifier constructor and estimate them from the integral image in the AiClassifier::classify() function:
int HaarFeatures::load(const wchar_t* file, unsigned int object_width, unsigned int object_height);int HaarFeatures::unload();int HaarFeatures::estimate(const vec2Di& integral_image, unsigned int dx, unsigned int dy, const HaarFeatures* pprev = 0);
Collapse |
Copy Code
int HaarFeatures::load(const wchar_t* file, unsigned int object_width,
unsigned int object_height)
{
unload();
FILE* fp = _wfopen(file, L"rt");
if (fp == 0)
return -1;
unsigned int nfeatures;
if (fwscanf(fp, L"%d", &nfeatures) != 1)
return -2;
m_feature_vector = new vec2D(1, nfeatures);
for (unsigned int i = 0; i < nfeatures; i++) {
wchar_t str[256] = L"";
unsigned int nrects;
if (fwscanf(fp, L"%s %d", str, &nrects) != 2) {
unload();
return -3;
}
Feature feature;
feature.name = std::wstring(str);
for (unsigned int j = 0; j < nrects; j++) {
Rect rect;
float coords[4] = {0.0f, 0.0f, 0.0f, 0.0f};
if (fwscanf(fp, L"%g %g %g %g %d", &coords[0], &coords[1],
&coords[2], &coords[3],
&rect.sign) != 5) {
unload();
return -4;
}
rect.left = int((float)object_width * coords[0]);
rect.top = int((float)object_height * coords[1]);
rect.right = int((float)object_width * coords[2]);
rect.bottom = int((float)object_height * coords[3]);
feature.rects.push_back(rect);
}
m_features.push_back(feature);
}
fclose(fp);
m_object_width = object_width;
m_object_height = object_height;
m_object_size = m_object_width * m_object_height;
return 0;
}
void HaarFeatures::unload()
{
m_features.clear();
m_object_width = 0;
m_object_height = 0;
m_object_size = 0;
if (m_feature_vector != 0) {
delete m_feature_vector;
m_feature_vector = 0;
}
}
int HaarFeatures::estimate(const vec2Di& integral_image,
unsigned int dx, unsigned int dy,
const HaarFeatures* pprev)
{
if (m_feature_vector == 0)
return -1;
m_feature_vector->set(0.0f);
unsigned int index = 0;
if (pprev != 0)
index = pprev->get_feature_vector().length();
for (unsigned int i = index; i < (unsigned int)m_features.size(); i++) {
int sum = 0;
Feature& feature = m_features[i];
for (unsigned int j = 0; j < (unsigned int)feature.rects.size(); j++) {
Rect& rect = feature.rects[j];
Rect coords;
coords.left = (dx + rect.left) - 1;
coords.top = (dy + rect.top) - 1;
coords.right = (dx + rect.right) - 1;
coords.bottom = (dy + rect.bottom) - 1;
unsigned int A = integral_image.get(coords.top, coords.left);
unsigned int AB = integral_image.get(coords.top, coords.right);
unsigned int AC = integral_image.get(coords.bottom, coords.left);
unsigned int ABCD = integral_image.get(coords.bottom, coords.right);
unsigned int D = ABCD + A - (AB + AC);
if (rect.sign > 0)
sum += D;
else
sum -= D;
}
(*m_feature_vector)(0, i) = (float)sum;
}
m_feature_vector->div(float(m_object_size) * 255.0f);
for (unsigned int i = 0; i < index; i++)
(*m_feature_vector)(0, i) = pprev->get_feature_vector()(0, i);
return m_feature_vector->length();
}m_feature_vector is normalized by dividing by the size of the object and 255, so processing objects at different scales will result in equal 'scale' feature values.
ObjectMap is simply a placeholder for the output of the last classifier from the cascade. That output is inspected at 5x5 pixel squares for a maxima, and if it exceeds the predefined detection threshold, it is used as a location of the found object.
The main part of the lib is the HaarDetector class. It provides the following functions you need to use in that order only to add the sizes of detected objects, load classifiers, initialize the class, and continue with detection:
void HaarDetector::add_object_size(unsigned int object_width, unsigned int object_height);int HaarDetector::load_skin_filter(const wchar_t* fname);int HaarDetector::add_ai_classifier(const wchar_t* classifier_file, const wchar_t*features_file);int HaarDetector::init(unsigned int image_width, unsigned int image_height);int HaarDetector::detect_objects(const vec2Di* y, char** r = 0, char** g = 0, char** b = 0, const vec2Di* search_mask = 0);
To unload and un-initialize, use these functions:
void HaarDetector::clear_object_sizes();void HaarDetector::unload_skin_filter();void HaarDetector::clear_ai_classifiers();void HaarDetector::close();
Collapse |
Copy Code
void HaarDetector::add_object_size(unsigned int object_width, unsigned int object_height)
{
ObjectSize osize;
osize.width = object_width;
osize.height = object_height;
m_object_sizes.push_back(osize);
osize = m_object_sizes[0];
m_dx = osize.width / 2;
m_dy = osize.height / 2;
for (unsigned int i = 1; i < (unsigned int)m_object_sizes.size(); i++) {
const ObjectSize& posize = m_object_sizes[i];
if (posize.width < osize.width) {
osize.width = posize.width;
m_dx = osize.width / 2;
}
if (posize.height < osize.height) {
osize.height = posize.height;
m_dy = osize.height / 2;
}
}
}
void HaarDetector::clear_object_sizes()
{
m_object_sizes.clear();
}
int HaarDetector::load_skin_filter(const wchar_t* fname)
{
unload_skin_filter();
m_skin_filter = new AiClassifier(fname);
if (m_skin_filter->status() != AiClassifier::CLASSIFIER)
return m_skin_filter->status();
if (m_skin_filter->get_input_dimension() != 3) {
unload_skin_filter();
return -1;
}
return 0;
}
void HaarDetector::unload_skin_filter()
{
if (m_skin_filter != 0) {
delete m_skin_filter;
m_skin_filter = 0;
}
}
int HaarDetector::add_ai_classifier(const wchar_t* classifier_file,
const wchar_t* features_file)
{
if (m_object_sizes.size() == 0)
return -1;
AiClassifier* pai_classifier = new AiClassifier(classifier_file, features_file,
m_object_sizes);
if (pai_classifier->status() !=
(AiClassifier::CLASSIFIER | AiClassifier::FEATURE_EXTRACTOR)) {
delete pai_classifier;
return -2;
}
else {
m_ai_classifiers.push_back(pai_classifier);
return 0;
}
}
void HaarDetector::clear_ai_classifiers()
{
for (unsigned int i = 0; i < (unsigned int)m_ai_classifiers.size(); i++) {
AiClassifier* pai_classifier = m_ai_classifiers[i];
delete pai_classifier;
}
m_ai_classifiers.clear();
m_status = -1;
}
int HaarDetector::init(unsigned int image_width, unsigned int image_height)
{
if (m_object_sizes.size() == 0)
return -1;
if (m_ai_classifiers.size() == 0)
return -2;
AiClassifier* pai = m_ai_classifiers[m_ai_classifiers.size() - 1];
if (pai->ai_type() != AiClassifier::SIGMOID_ANN)
return -3;
m_image_width = image_width;
m_image_height = image_height;
m_integral_image = new vec2Di(get_image_height(), get_image_width());
for (unsigned int i = 0; i < (unsigned int)m_object_sizes.size(); i++) {
const ObjectSize& osize = m_object_sizes[i];
ObjectMap* omap = new ObjectMap(get_image_width(), get_image_height(),
osize.width, osize.height);
m_object_maps.push_back(omap);
}
m_search_mask = new vec2Di(get_image_height(), get_image_width());
m_tmp_search_mask = new vec2Di(get_image_height(), get_image_width());
m_status = 0;
return 0;
}
void HaarDetector::close()
{
if (m_integral_image != 0) {
delete m_integral_image;
m_integral_image = 0;
}
for (unsigned int i = 0; i < (unsigned int)m_object_maps.size(); i++) {
ObjectMap* omap = m_object_maps[i];
delete omap;
}
m_object_maps.clear();
if (m_search_mask != 0) {
delete m_search_mask;
delete m_tmp_search_mask;
m_search_mask = 0;
m_tmp_search_mask = 0;
}
m_status = -1;
}
int HaarDetector::detect_objects(const vec2Di* y,
char** r, char** g, char** b,
const vec2Di* search_mask)
{
if (status() < 0)
return status();
estimate_motion_percent(search_mask);
m_search_mask->set(1);
if ((r != 0 && g != 0 && b != 0) && m_skin_filter != 0)
skin_filter(r, g, b, search_mask);
if (search_mask != 0)
m_search_mask->and(*search_mask);
m_pimage = y;
compute_integral_image(*y);
run_classifiers();
return search_faces();
}
void HaarDetector::run_classifiers()
{
float oval = 0.0f;
for (unsigned int i = 0; i < (unsigned int)m_object_maps.size(); i++) {
const ObjectMap* pom = m_object_maps[i];
unsigned int dx = pom->get_object_width() / 2;
unsigned int dy = pom->get_object_height() / 2;
vec2D& omap = pom->get_object_map();
omap.set(0.0f);
for (unsigned int y = dy; y < omap.height() - dy; y++) {
for (unsigned int x = dx; x < omap.width() - dx; x++) {
if ((*m_search_mask)(y, x) == 0)
continue;
for (unsigned int j = 0; j <
(unsigned int)m_ai_classifiers.size(); j++) {
const AiClassifier* pprev_ai = 0;
if (j > 0)
pprev_ai = m_ai_classifiers[j - 1];
AiClassifier* pai = m_ai_classifiers[j];
int cls = pai->classify(*m_integral_image, i,
x - dx, y - dy, &oval, pprev_ai);
if (j != (unsigned int)m_ai_classifiers.size() - 1) {
if (cls < 0) {
omap(y, x) = 0.07f;
break;
}
}
else
omap(y, x) = oval;
}
}
}
}
}detect_objects() will return the number of detected objects, if any, you may query with:
inline unsigned int HaarDetector::get_detected_objects_number() const;inline const Rect* HaarDetector::get_detected_object_rect(unsigned int i) const;inline const vec2Di* get_detected_object(unsigned int i) const;
Additionally, you may change the detection sensitivity in the range of (0.0 - 25.0), which means (detecting everything - detecting nothing)
inline void detection_sensitivity(float th);
The original image is resized to 8 times smaller. So the 640x480 image will be just a 80x60 image, and looking for a 19x19 object is the same as looking for a 152x152 sized object on the original image. The corresponding code from theOnTimer event is shown below:
Collapse |
Copy Code
void CVidCapDlg::OnTimer(UINT_PTR nIDEvent)
{
m_ImgResize.resize(pData);
m_MotionDetector.detect(*m_ImgResize.gety(), m_HaarDetector);
if (m_HaarDetector.status() == 0) {
nObjects = m_HaarDetector.detect_objects(m_ImgResize.gety(),
m_ImgResize.getr(),
m_ImgResize.getg(),
m_ImgResize.getb(),
&m_MotionDetector.get_motion_vector());
}
}Results
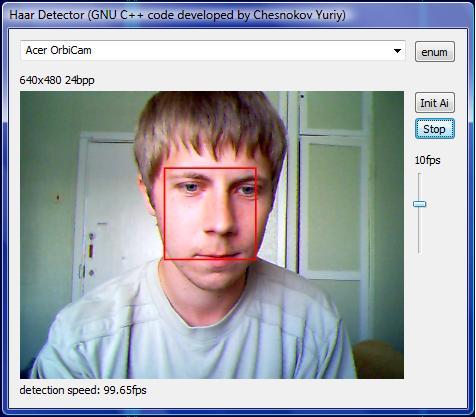
Now some detection results for a single scale only first (finding a 152x152 face in a 640x480 image, which is equal to the 19x19 face in a 80x60 image):
Comment these lines out at:
Collapse |
Copy Code
void CVidCapDlg::OnBnClickedInitAiButton()
{
m_HaarDetector.add_object_size(19, 19);
}
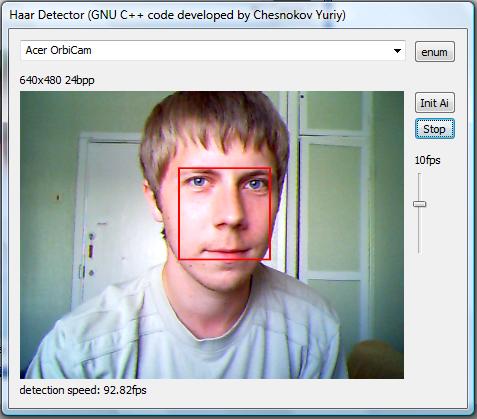
Very little motion - 99fps, 92fps
More motion - 81fps
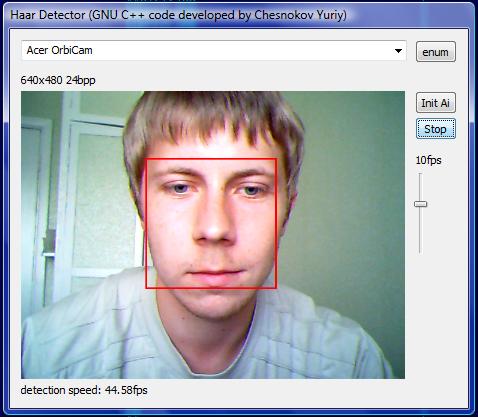
Now looking over multiple scales for 19x19, 23x23, 27x27 faces:
Medium motion - 44fps, 48fps
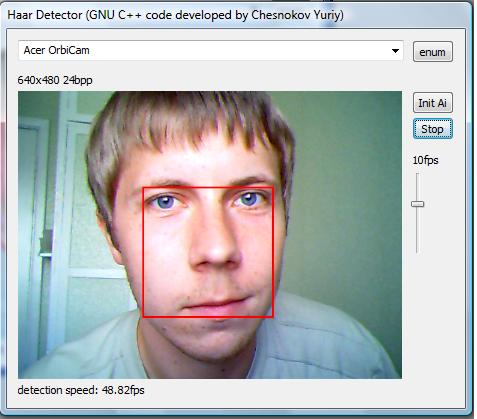
Very Fast Results (Updated 10/07/2008)
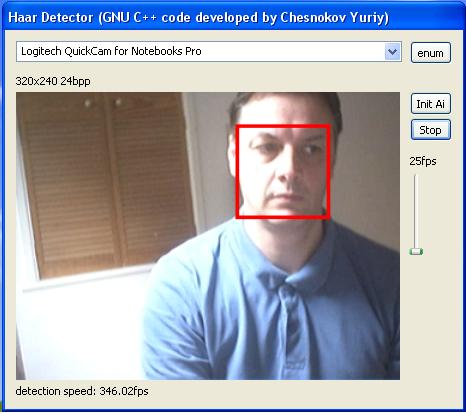
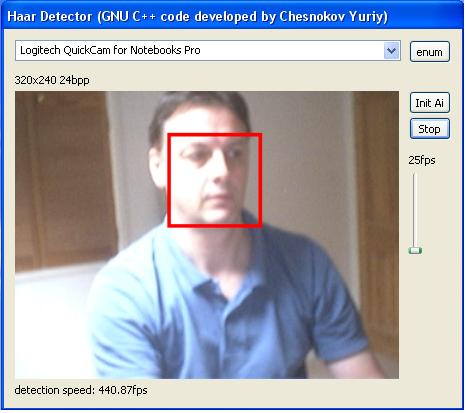
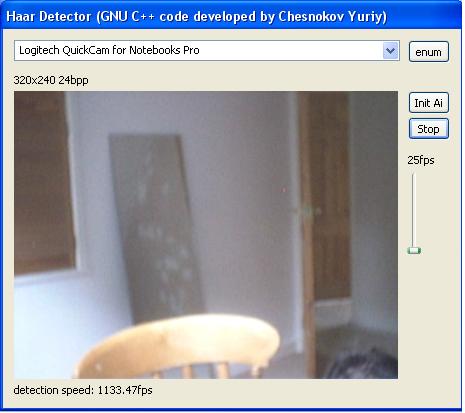
Some of the users of the lib gave me their fps results on the latest quad processor machine, detecting faces at the same 80x60 image (here 320x240 downscaled 0.25 times) at three scales: 19x19, 23x23, 27x27. As you know, the lib is written and compiled without OpenMP support, so it is not possible that the processor itself parallelizes the binary code during the execution process. Nor is the downscale from 320x240 is so fast compared to the downscale from 640x480. It takes just a few ms in both cases, and 90% of the time is spent on the detection process. Anyway, the figures are awesome, incredible, unbelievable. It runs at 340fps+ while capturing a video at 25fps and the processor usage is 7-9%.
Medium motion - 346fps, 440fps
No motion - 1133fps
CPU usage with 346fps, 440fps and 1133fps
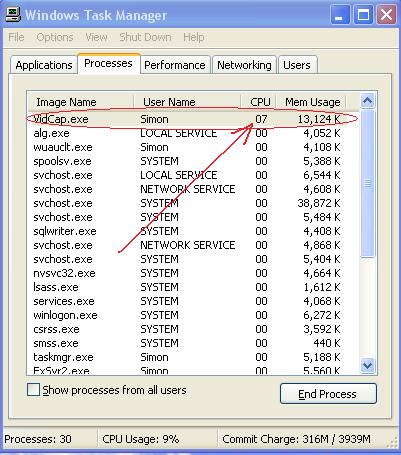
He has slower detection rates at the PCA based lib just about 300fps. But still the quad machine is great. Consider OpenMP introduced, it will run 4x400fps = 1600fps? It leaves a lot of time for face recognition, gender, age classification etc... The machine will see you at real time, scary, while spending 7% of CPU power. The future is now, 'HAL, open the bay door'.
Points of Interest
I presume the project is great. A lot of effort was spent on writing the feature text files, and my computer was sweated training the classifiers cascade. You may also devise more features and add them; also consider different classifiers, especially ones that avoid floating point calculation. That should lead to even greater speeds. You can also use statistical significance tests to choose more discriminative features for the first stages of a cascade.
